The most interesting, central property of trees, I think, is that they are recursive. Each node in the tree is, itself, a tree. Sets also have this property, they can be broken into subsets. Trees are trees of trees, and sets are sets of sets. It's "trees all the way down", just as it is "sets all the way down".

But sets have another important feature that trees cannot replicate well. Sets can overlap.

This is, I think, a fundamental problem with tree-based organizational systems.
For example, say I have many photos of my pets, and I'm organizing them into folders. I have one folder for dog pictures, and another for cat pictures. As I'm organizing, I find a photo which includes both a cat and a dog together. This photo should be put into both folders, but the tree structure does not allow for this.
So... what do? Here's some obvious ideas.
1 - Commit to trees, and simply do not choose overlapping subsets.
We can split sets into subsets however we like, so we're free to choose subsets with no overlap.
This can be impractical, though, because our choice of categorization is often determined by other, more important factors.
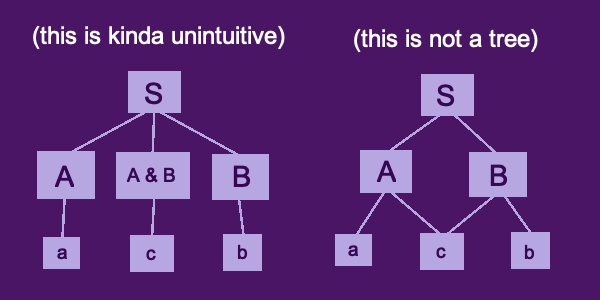
2 - Make a new subset to represent the overlap. This is a little jank. It means, for example, that your cat folder will not contain all of your cat pictures. (See the left side of the below diagram.)
3 - Abandon the tree structure, and allow a node to have multiple parents. (See the right side of the below diagram.)
With websites, I don't think there's much issue with this. Websites are designed as freeform networks already, so there isn't much pressure to conform to a tree structure. But with, for example, file directories, where the tree structure is already baked-in, you'll have to either make a copy of the file for each directory, or use an alias. The latter is obviously preferable, but it still means you're carrying around references to things that won't necessarily change in response to changes in the thing itself (eg: if I delete a file, its alias will still exist). It can be a slight hassle, but this is only a problem because file management systems are already fundamentally built as trees. You're trying to fit a non-tree structure into something that really wants to be a tree.
2 - Make a new subset to represent the overlap. This is a little jank. It means, for example, that your cat folder will not contain all of your cat pictures. (See the left side of the below diagram.)
3 - Abandon the tree structure, and allow a node to have multiple parents. (See the right side of the below diagram.)
With websites, I don't think there's much issue with this. Websites are designed as freeform networks already, so there isn't much pressure to conform to a tree structure. But with, for example, file directories, where the tree structure is already baked-in, you'll have to either make a copy of the file for each directory, or use an alias. The latter is obviously preferable, but it still means you're carrying around references to things that won't necessarily change in response to changes in the thing itself (eg: if I delete a file, its alias will still exist). It can be a slight hassle, but this is only a problem because file management systems are already fundamentally built as trees. You're trying to fit a non-tree structure into something that really wants to be a tree.
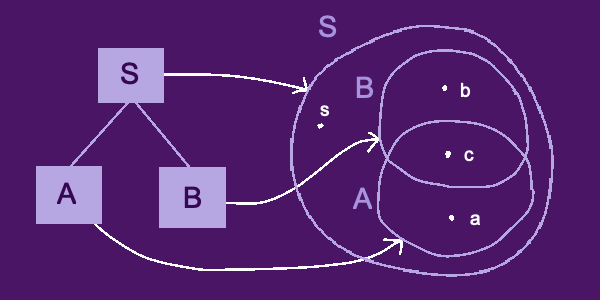
I realize that option 3 is very similar to a "tagging" system. Tags are a closer representation of subsets, I think, easily handling overlap. There are certainly ways to misuse them, but I honestly don't see any fundamental issues? Maybe trees were a mistake, and we should've been using tags all this time...
A good name for option 3 might be "hierarchical tagging"? That is, a tree of tags, where each parent tag links to all of its child tags' items (for a tree with parent A and children B and C, sorting by A is shorthand for sorting by B||C). So, in the earlier example, I'd have the parent tag pets, with 2 child tags dogs and cats. The pets tag would link to all photos with any of its sub-tags, the dogs or cats tags. Maybe photos should also be able to have the pets tag itself, or maybe restricting ourselves to tagging with leaf-tags would be preferable, I'm not sure. The dogs and cats tags would link to all their corresponding tagged photos, obviously. A photo can have more than one tag, like a photo with both a cat and dog, which means it would appear when sorting by either of its tags. In the case where each item has exactly 1 tag, this would be equivalent to a tree.
I can't help but notice the lack of tag-based file managers, however. This is a sign that there might be some issue I haven't noticed. To my knowledge, there are no operating systems built, from the ground up, with tag-based file management systems. Tagging systems are likely significantly different from trees under-the-hood, so there might be more challenges when it comes to implementation. It could just be a matter of self-sustaining tradition, though. Hierarchical file systems are likely derived from physical filing systems, after all, and tagging systems aren't really an option for physical organization.
Anyway...
Unlike my FNaFposts, this is a subject studied more seriously and rigorously by many people, including academics, so there is surely lots of research and theory out there I'm not aware of. Here is one proposal I stumbled on for a tag-based file management system. This person has clearly put in much, much more thought than I have, and even they seem unsure of the practical technicalities that would come with such a system, so clearly there is a lot of complexity to this subject.